

AfterQuery @AfterQuery
Applied research lab curating data solutions to accelerate foundation model development. afterquery.com Joined February 2025-
Tweets28
-
Followers1K
-
Following6
-
Likes64
Blog: afterquery.com/blog/on-policy… Interested in research or other roles at AfterQuery? Check this out! afterquery.com/careers
@AfterQuery will be at ICLR next week! We’ll be at booth 404. Happy to chat about anything related to tool use/agents, RL environments, code gen, or evals. DM me if you wanna meet up!

AfterQuery post-trained GPT-OSS-20B using Harbor + Tinker and saw a 14% bump on TB2 performance. Love seeing people pick up Harbor for more than just evals.


YC and @GoogleDeepMind are hosting the Multimodal Frontier Hackathon this Saturday. Most AI apps still don't utilize the full multimodal stack. So we’re giving you access to Gemini 3.1, Lyria, & NanoBanana 2 to see what you can build! Sign up at: events.ycombinator.com/deepmind-march…

Introducing IDE-Bench! A multi-language, full-stack benchmark evaluating LLMs acting as autonomous IDE agents IDE-Bench assesses agents' ability to navigate, reason, and modify complex repositories using the same tools available in modern AI-native IDEs like Cursor Models tested from @AnthropicAI, @OpenAI, @Alibaba_Qwen, @GoogleDeepMind, @xai, @deepseek_ai, @Meta, and @cohere Check out the full results at ide-bench.com!
Our findings show that current models lack the ability to perform even the most basic tasks in high-impact, real-world domains like quantitative trading. We hope Market-Bench can serve as a shared framework to evaluate models’ understanding of trading strategies and code generation for quantitative finance. Excited to track how these capabilities evolve!
Leaderboard: marketbench.ai Paper: arxiv.org/abs/2512.12264
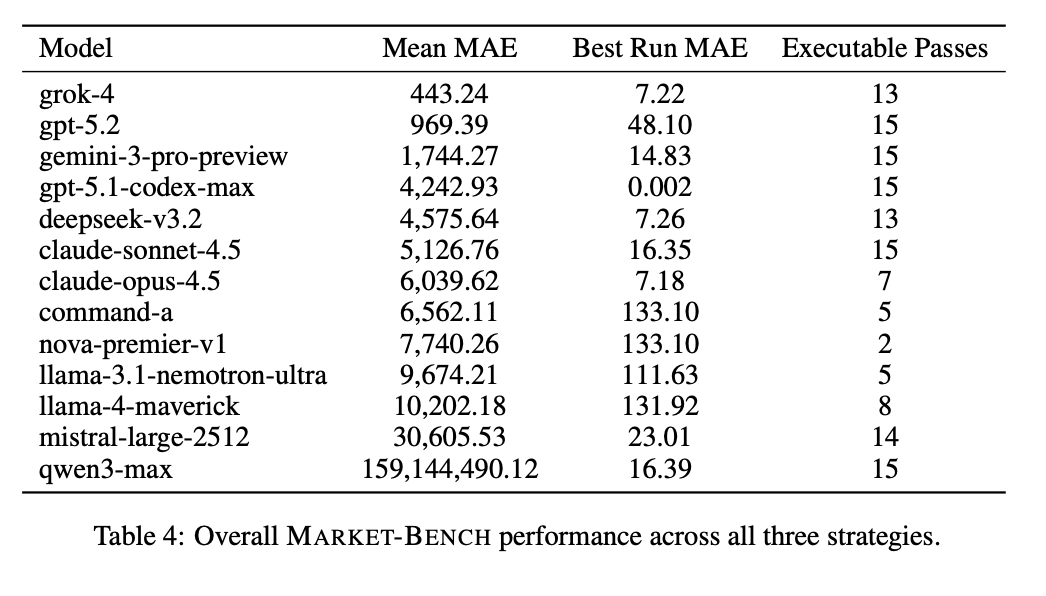
Introducing Market-Bench by @AfterQuery! The first-of-its-kind benchmark on LLMs for quantitative finance. We challenged models to attempt a frequent introductory quantitative trading task: coding an executable backtester from a natural-language strategy description and market assumptions. > 13 models build backtesting systems for directional, pair trading, and delta hedging strategies > evaluated on reliability (executable passes) and accuracy (MAE) across 5 attempts per strategy > real order book data with exchange delays and liquidity constraints > @xAI’s Grok 4 achieved the overall lowest mean MAE (deviation from the golden backtest), followed closely by @OpenAI’s GPT 5.2 > @AnthropicAI's Sonnet 4.5 and @AlibabaGroup's Qwen 3 Max at perfect executability but high MAE > Models from @Meta, @Amazon, @NVIDIA, and @Cohere continued to fail to produce executable backtesters Leaderboard & full paper below!
How far can vibe coding actually go? Introducing App-Bench by @AfterQuery, a benchmark for end-to-end web app development. We tested 6 production web apps on 10 coding agents from @OpenAI, @GoogleDeepMind, @AnthropicAI, @cursor_ai, @budapp, @v0, @boltdotnew, @Replit, and @Lovable. One shot generation. Zero human edits. 4,530 evaluations.

Really excited to have contributed to this sick creative vision and brought the @AfterQuery website to life 😎😎
Today, humanity is shackled by scarcity of expertise. When expertise becomes infinitely scalable, humans will be freed to tackle problems we can't even conceive of today. Introducing @AfterQuery. We’re building a world where expertise is abundant. Domain by domain, profession
Today, humanity is shackled by scarcity of expertise. When expertise becomes infinitely scalable, humans will be freed to tackle problems we can't even conceive of today. Introducing @AfterQuery. We’re building a world where expertise is abundant. Domain by domain, profession by profession, AfterQuery is crafting datasets that encode excellence into forms that machines can learn. Data is the final frontier.
@shrawberryy @sashabirukoff shrawberry 🙌
The frontier begets the frontier. I highly recommend reading @jaminball's latest Clouded Judgement article which spells out the AfterQuery thesis (thread)



Siva @FILMENTHUSIATSK
0 Followers 43 Following
kira 💢 @collinsokore3
20 Followers 124 Following
Kojo Patrick @_kojopatrick
423 Followers 3K Following
Moyo @moyor_d
198 Followers 191 Following
Dylan Zhang @dylan_works_
1K Followers 7K Following Looking for Internships & Collab (Start-up's welcome!!) Modeling Language @UofIllinois CS PhD | SR @GoogleDeepMind | Ex. @MSFTResearch Intern


Daniel Marin | nexus.... @danielmarinq
102K Followers 763 Following Founder & CEO @NexusLabs // prev. @Stanford

Tonex d Chad @Tboy00144821
718 Followers 2K Following Defi Enthusiast || Shiller || Community Manager || Moderator || Bot integrator ll Chat engager || Reply Guy Nitrograph
bigleo @Kingleo_72
272 Followers 360 Following | Forex trader |Writer| Branding expert | Backend dev|
katie 🍊 @inwkatie
84 Followers 846 Following 🪿🍁⁂ @uwaterloo statistics kid w big love for product, art, people, & dad jokes
elena sakach @elena_sakach
1K Followers 5K Following partner @GVteam // prior: @coatuemgmt basis, blockaid, humans&, ramp, stripe, tennr, waymo, wealth
nectarios @nectarios
4K Followers 5K Following Partner @ Amiral Ventures, mountain biker, souvlaki lover. Make Canadian Tech great.
Sørd 🗽• @_solahudeen
2K Followers 2K Following NFTs || AI || Hustler || Sports Content Creator ~Sørd of all Niche~
Ghost burns | edu/acc @ghost_burns_
295 Followers 2K Following Student | Lead @BaDEthiopia | @Dev3Pack Fellow | @cyfrin Ambassador | Prev amb @KRNL_xyz| Blockchain Advocate | Web3 Dev | ኢትዮጲያዊ 🇪🇹

Brandon Yifan Yang @brandonyyang02
18 Followers 139 Following Robot + AI Research at @AfterQuery | Robotics at @Penn | Prev at @UVA
y2j👁 @y2j_021
1K Followers 5K Following @brypto_official associate ambassador community manager/moderator XC9V744Q
Nathan @arcane_bloom
234 Followers 2K Following • Curiositymaxxing • ML + Software • UG @iitmadras '26 • Daily Learning Logs @senthil_twt
Alaa Adel @alaaade15722
0 Followers 18 Following ﴿رَبِّ إِنِّي لِمَا أَنزَلْتَ إِلَيَّ مِنْ خَيْرٍ فَقِيرٌ﴾
Alex Dong @alexdong
2K Followers 875 Following RL for domains where human judgment is critical. AI Lead/Cofounder @tacitco. Epeeist. Gardener. Reader. I love low-ego, positive, competent and earnest people.

BEEMAX @Beemax01
2K Followers 1K Following Law. Football. Politics. Money. Power.Wildlife.Motivation. viral Clips.



blessed jnr @jnr_saint22
21 Followers 708 Following Music Curator 🎧 | Wizkid FC 💚 | ⚪ Real Madrid Afrobeats • Trends • Daily Updates Vibes only| cruise. Stay tuned


Otto von Zastrow @OttoZastrow
453 Followers 680 Following Founder of https://t.co/i9FmQljTEu Building the genAI research and drafting platform for lawyers | CS at ETH Zürich
Odunayor @Odunayor1
4K Followers 3K Following Web3 Content Writer || Community Builder || Collab || Machine Learning Analyst || COYG🔴⚪|| Ambassador @partykols


masterpiece @kiyotaakka
0 Followers 65 Following
Devansh Shah @theboyinatux
150 Followers 563 Following just another stochastic neuron learning to fire. MBA @ucberkeley, prev. operator roles @google, @indeed, @sarvamai. CS @iiit_hyderabad
Kiarie Nation @kiarieNation
2 Followers 44 Following Disrupting The Peace of an Oppressing Government Is a Moral Obligation🇰🇪
Kaycee @OGB_The_Second
101 Followers 1K Following Lecturer with PTSD from project defenses, Escaped fibre optics thinking lecturing would be easier, First born still waiting for family refunds abi returns
Magi「☄️G☄️�... @Magi83040733880
115 Followers 315 Following
Tee @Tee111268
0 Followers 20 Following Web3 Community Builder | DAO Contributor | Learning DeFi, NFTs & Crypto
Daniel Bogale @daniel_bogale_
109 Followers 214 Following Senior Software Developer | AI & Full-Stack Applications | Automation Engineer (n8n) | Built platforms for 10K+ users | A2SV Trainee (Backed by Google)
Jeph @sparo_jef
335 Followers 1K Following Supporting early-stage startups with administrative systems & customer experience workflows | Helping founders scale without operational chaos.
Oluwashindara @CryptoDare1
303 Followers 336 Following Redefining Mathematics for the modern student. Specialized curriculum support, exam prep, and simplified tutorials. Making math fast, easy and accessible.



Adeoye Gbade @BigGbade
3 Followers 139 Following



John Schulman @johnschulman2
75K Followers 2K Following Recently started @thinkymachines. Interested in reinforcement learning, alignment, birds, jazz music


Carlos Georgescu @CarlosGeorgescu
389 Followers 1K Following @afterquery interested in AI research, quantitative finance & poker
Spencer Mateega @spencermateega
2K Followers 2K Following ceo @afterquery. prev statistics + finance + cs @ wharton / penn, @silverlake_news, @google, @morganstanley, @metaYou might like



















