

Jing En Cheam ジャン・ジンエン @CoderJing
working on small miracles every day - The Pragmatic Programmer 👨💻 === 🧙♂️ je-dev.com Malaysia Joined September 2023-
Tweets15
-
Followers2
-
Following121
-
Likes105

@drainpipe_ @AdamRackis @Cal_Irvine TC39 hasn't ignored it, you assume wrongly. Graydon Hoare when he and I were working on ES4 attended 754r meetings. We didn't get Decimal into ES4 of course, but thanks to TC39 members (esp. BBG/@paprocki & @littledan) working on it, it's now at stage 1: github.com/tc39/proposal-….

🚨🚨 90% Of Code Is AI Generated - 650,000,000 Check Boxes In One Website 🚨🚨

React Digest is a free carefully curated weekly newsletter for React developers to become better front-end engineers.
#leetcode That's my first February batch.

🔥 Fun fact: emojis can be made of MULTIPLE emojis javascript can iterate through every 🤦 in a 👨👩👧👦

Worm hole😂

Advent of Code 2023 Day 11 #AdventOfCode

Advent Of Code is so much fun! #AdventOfCode

Do you use Pino for logging, or are you thinking about it? In this blog, I looked at: ‣ The benefits of Pino ‣ Getting started ‣ Key features ‣ Pino's advantages over other logging libraries ‣ How to log with Pino & @Platformatic hubs.ly/Q027Bt4c0
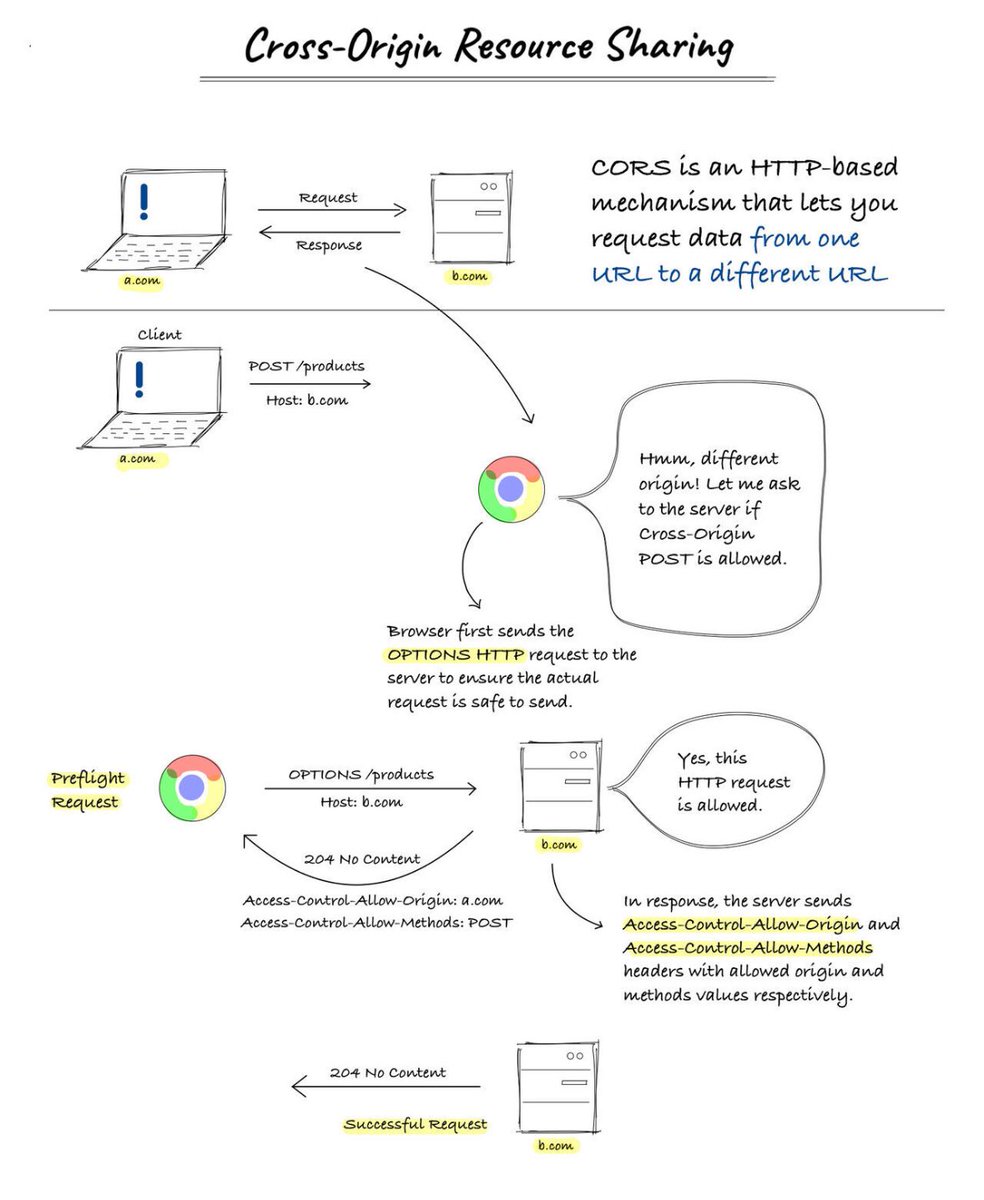
𝗪𝗵𝗮𝘁 𝗶𝘀 𝗖𝗿𝗼𝘀𝘀-𝗢𝗿𝗶𝗴𝗶𝗻 𝗥𝗲𝘀𝗼𝘂𝗿𝗰𝗲 𝗦𝗵𝗮𝗿𝗶𝗻𝗴 (𝗖𝗢𝗥𝗦)? Browsers use CORS, a method, to prevent websites from requesting data from different URLs. A request from a browser includes an origin header in the request message. The browser allows it if it gets to the server of the exact origin; if not, the browser blocks it. We can deal with CORS issues on the backend. Cross-origin requests require that the values for origin and 𝗔𝗰𝗰𝗲𝘀𝘀-𝗖𝗼𝗻𝘁𝗿𝗼𝗹-𝗔𝗹𝗹𝗼𝘄-𝗢𝗿𝗶𝗴𝗶𝗻 in the response headers match and it is set by the server. When you add an origin to the backend code, the CORS middleware only permits this URL to communicate with other origins and utilize it for cross-origin resource requests. There are two ways to fix CORS issues: 𝟭. 𝗖𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗲 𝘁𝗵𝗲 𝗕𝗮𝗰𝗸𝗲𝗻𝗱 𝘁𝗼 𝗔𝗹𝗹𝗼𝘄 𝗖𝗢𝗥𝗦 Server can let all domains with 𝗔𝗰𝗰𝗲𝘀𝘀-𝗖𝗼𝗻𝘁𝗿𝗼𝗹-𝗔𝗹𝗹𝗼𝘄-𝗢𝗿𝗶𝗴𝗶𝗻: *. This actually turns off same-origin policy, which is not recommended. Another optin would be only to allow particular domain, which is better option, e.g., 𝗔𝗰𝗰𝗲𝘀𝘀-𝗖𝗼𝗻𝘁𝗿𝗼𝗹-𝗔𝗹𝗹𝗼𝘄-𝗢𝗿𝗶𝗴𝗶𝗻: 𝗵𝘁𝘁𝗽𝘀://𝘀𝗼𝗺𝗲𝗱𝗼𝗺𝗮𝗶𝗻.𝗰𝗼𝗺. 𝟮. 𝗨𝘀𝗲 𝗮 𝗣𝗿𝗼𝘅𝘆 𝗦𝗲𝗿𝘃𝗲𝗿 We can use a proxy server to call external API. It acts as a middleware between client and the server. If the server doesn't return proper headers defined by CORS, we can add them in the proxy. Image credits: RapidAPI #softwareengineering #programming #api #apidesign #techworldwithmilan
Red flags in a React codebase 🚩 functions named handleClick,handleSubmit 🚩 preventDefault 🚩 useMemo 🚩 fetch inside useEffect 🚩 <div onClick/> 🚩 a "hooks" directory 🚩 css files 🚩 icon library in package.json

JWT Token Structure Simplified:

A Monolithic database is NOT bad. But sometimes it may not be enough. Uber realized this a few years back when they were experiencing a whopping 20% trip growth every month. It meant that soon their main trip storage database was going to run out of storage volume and IOPS. Unless they did something about it… Like most startups in the early days, Uber’s backend system was also monolithic. There were 3 main parts to this system: - Real-time services - Backend services - PostgreSQL DB This architecture was good enough for Uber’s initial operations. But it simply couldn’t keep up with its growth trajectory. Something had to be done… They decided to refactor the system to move the Trip data into a separate scalable data store. “Why only the Trip data?” - you may ask. Because it was taking up the largest percentage of the overall pie. It also contributed to the most IOPS. There were a few important requirements for the new Trip store: ✅ Should be horizontally scalable in storage capacity and IOPS ✅Should have high write availability. They were okay to trade off short-term read availability ✅ Should support secondary indexes so that trips can be looked up by various parameters ✅ No downtime for operations such as expanding storage, taking backups, and so on. Ultimately, the decision was made to go for a column-oriented, schemaless database. What does it mean? It meant organizing data as JSON blobs in a grid indexed by Trip-UUID. Since the DB was schemaless, new columns and fields could be added without any reconfiguration. This was in line with their philosophy of rapid application development. Unfortunately, Uber didn’t find a suitable NoSQL database with the above characteristics. Therefore, they decided to build their own sharded data store on top of MySQL. A few cool characteristics of this database were: - Append-only (no updates data model) - Buffered writes - Sharding - Sharded secondary indexes As a first step to migration, they targeted the below design: The lib/tripstore component exposed an API that could communicate with a schemaless-based implementation. This component had a switch so a query could be directed to either PostgreSQL or Schemaless. A few important phases of the project were: 1 - Changing all trip IDs to trip-UUIDs 2 - Building the Column layout for the new Trips data model 3 - Backfilling data from PostgreSQL to Schemaless 4 - Mirrored writes to PostgreSQL and Schemaless 5 - Rewriting all queries to work with Schemaless 6 - Lots of validation There were also many valuable lessons learned along this whole journey: - Always use UUIDs even when starting out. - Keep the data layer simple to debug and troubleshoot - The correct data model comes through trial and error - Don’t waste too much time on the final migration. It will always be a moving target. === That’s all for now! If you enjoyed this explanation of Uber’s migration from monolithic DB to Schemaless, don’t forget to: - Book a ride for the LIKE button - REPOST so that everyone can learn from Uber’s approach - BOOKMARK to revisit it later - Follow me for more posts like this.




Learn Data Science FREE with Certificates: ❯ Python freecodecamp.org/learn/scientif… ❯ SQL openclassrooms.com/courses/207148… ❯ R boardinfinity.com/micro-learning… ❯ Excel intellipaat.com/academy/course… ❯ PowerBI learn.microsoft.com/training/paths… ❯ Tableau mygreatlearning.com/academy/learn-… ❯ Mathematics & Statistics matlabacademy.mathworks.com ❯ Data Analysis cognitiveclass.ai/courses/data-a… ❯ Data Visualization cognitiveclass.ai/courses/data-v… ❯ Machine Learning simplilearn.com/learn-machine-… ❯ Deep Learning kaggle.com/learn/intro-to…
This brilliant technique for handling database queries literally saved Discord. It helped them store trillions of messages and fetch them without bringing their DB cluster to its knees. The technique is called Request Coalescing. And it’s too good to ignore. But what’s so special about it? If multiple users are requesting the same row at the same time, why not query the database only once? This is exactly what Request Coalescing helps us achieve. Here’s what happens under the hood: - The first user that makes a request causes a worker task to spin up in the data service - Subsequent requests for the same data will check for the existence of that task and subscribe to it - Once the initial worker task queries the database and gets the result, it will return the row to all subscribers at the same time. There are several pros to using Request Coalescing: - Efficient utilization of database resources - Ability to handle more concurrent requests without creating hot partitions - Reduce latency But there are some cons as well: - Implementation can be complex with regards to getting a fair distributed reader-write lock. Basically, multiple readers need to access the data simultaneously while preventing conflicting writes - Overall latency may go down, but certain requests will take more time Of course, this technique is NOT needed normally. But at a certain scale, it can actually save your business. === That’s all for now! If you enjoyed this post, don’t forget to: - Destroy the LIKE button - REPOST so that everyone can try Request Coalescing wherever applicable. - BOOKMARK for future reference - Follow me for more posts like this.

doll @MyersRicar
132 Followers 547 Following Finding peace in the volatility. Riding the waves of the digital ocean. 🌊 Not a signal provider, just a traveler. # Web3
wen👩🏻💻 @ds_wen_
25K Followers 13K Following 👋 senior data scientist. i do = data science + ai + lifelong learning with a growth mindset
SumitM @SumitM_X
45K Followers 1K Following 16 years In IT | Author of a bestselling Java book | All Books links in the pinned tweet https://t.co/NmsenbKiBW
Next.js @nextjs
283K Followers 16 Following The React Framework – created and maintained by @vercel.
Sumit Kumar @TweetsOfSumit
18K Followers 375 Following Founder 📈 @parqetapp Host of 🎙 @minimalempires Prev. @stripe
Stripe @stripe
285K Followers 561 Following Stripe builds programmable financial services. Help: @stripesupport. Read: @stripepress @WorksInProgMag. Status: @stripestatus.
Dmitrii Kovanikov @ChShersh
71K Followers 256 Following Dysfunctional Programming account #1. Senior SWE. I write C++ for money. ex-Haskell, ex-OCaml. All opinions are my own.
yifei e/λ (meetmeins... @yifever
11K Followers 2K Following ex-PHD CERN | femboy enjoyer | ??? in tokyo | whale stan | 有馬かな最推し | ことねP | never yifei yourself JP @AccPocari



Anthropic @AnthropicAI
1.3M Followers 35 Following We're an AI safety and research company that builds reliable, interpretable, and steerable AI systems. Talk to our AI assistant @claudeai on https://t.co/FhDI3KQh0n.
@levelsio @levelsio
890K Followers 3K Following 📸https://t.co/lAyoqmSBRX $100K/m 🛰https://t.co/ZHSvI2wjyW $44K/m 🎮https://t.co/jFirUbDgtZ $39K/m 🏡https://t.co/1oqUgfD6CZ $35K/m 👙https://t.co/RyXpqGuFM3 + @X $14K/m 🌍https://t.co/UXK5AFqCaQ $10K/m 💾https://t.co/T74ZwJ1F0C $0/m
Lemon Squeezy @lemonsqueezy
25K Followers 12 Following The all-in-one payments, tax, email and affiliate marketing platform for software companies
ThePolymathicEng @EngPolymathic
5K Followers 7 Following Official account of the Polymathic Engineer newsletter, written by @franc0fernand0. Algorithms, distributed systems, and software engineering. Subscribe here:
Adrian @adriann_xyz
581 Followers 225 Following ✳︎ Design Lead & Founder @vividmotionEN - Creative Technology & Design Studio ✳︎ Past clients: Meta, Cisco, Skechers, Soundcloud, Dribbble, Meta...
Antfroze @Antfroze
3K Followers 133 Following It's not a bug, it's a feature | 21 yo broke college student | coding since 12 yo | https://t.co/scFjkJIQUc | building https://t.co/v124KYhAKm
Wise @Wise
174K Followers 3K Following 160+ countries. 40+ currencies. Money for here, there and everywhere.

Fernando @Franc0Fernand0
51K Followers 241 Following Dad and husband • Software Engineer for 15+ years • Algorithms, Distributed Systems, System Design, Computer Vision
Hussein Nasser @hnasr
88K Followers 640 Following Backend and Database Courses https://t.co/Qonec4YftL YouTube https://t.co/FfDg8cnVCI Author of Root Cause https://t.co/x5hQ6JCIcw Engineer @esri
Wojciech Maj 🦋 @wo... @wojtekmaj91
731 Followers 328 Following Dad, husband, TypeScript developer. https://t.co/BugwTp5B38 https://t.co/upDCnKj9yT
Lucide Icons @lucide_icons
412 Followers 24 Following About Beautiful & consistent icon toolkit made by the community. Open-source project and a fork of Feather Icons.
Kubernetes @kubernetesio
323K Followers 86 Following #Kubernetes: open source production-grade container orchestration management. #CNCF #K8s
Dan ⚡️ @d4m1n
32K Followers 853 Following Shipped a bunch of profitable startups & doing videos on dev, design + marketing. Also likes pizza 🍕 ・ 🆕 https://t.co/SazZx8mMtN ・ All work → https://t.co/H9HiLm5IxN
Red Hat Ansible @ansible
76K Followers 780 Following Automation for Everyone. Simple, powerful, agentless automation language to describe your complete IT infrastructure.
containerd @containerd
18K Followers 65 Following The maintainers of containerd: an industry-standard container runtime with an emphasis on simplicity, robustness and portability.
Istio @IstioMesh
47K Followers 117 Following #Istio is an open platform that provides a uniform way to connect, manage, and secure microservices. ⛵️ Join our community: https://t.co/23fWuCAw1W
Kubecon_ @KubeCon_
44K Followers 66 Following The #Kubernetes & @CloudNativeFdn community conference. Join us at https://t.co/I1qXBvTytY #KubeCon + #CloudNativeCon
Helm @HelmPack
38K Followers 215 Following the package manager for @kubernetesio // a @CloudNativeFdn graduated project // check out Helm V3 now

HashiCorp, an IBM Com... @HashiCorp
103K Followers 146 Following HashiCorp helps you to automate multi-cloud & hybrid environments with Infrastructure & Security Lifecycle Management.
PrometheusMonitoring @PrometheusIO
52K Followers 87 Following An open-source service monitoring system and time series database.
Grafana @grafana
71K Followers 164 Following ☁️ Open observability cloud ☁️ Join the Grafana community 👇
Bitmovin @bitmovin
8K Followers 6K Following We are the Emmy award-winning category leader in video streaming infrastructure.
RabbitMQ @RabbitMQ
13K Followers 212 Following Open source multi-protocol distributed messaging and streaming tool. For technical Qs: https://t.co/rSmRWih2Io…. GitHub: https://t.co/4Uob3kJ0qs

TypeScript Daily @TypeScriptDaily
14K Followers 3 Following Daily TypeScript news and articles. Sister account of https://t.co/M5FGMV4Cva, a weekly email round-up of TypeScript links. Curated by @mariusschulz.
TypeScript @typescript
416K Followers 50 Following TypeScript is a language for application-scale JavaScript development. It's a typed superset of JavaScript that compiles to plain JavaScript.
Bytebytego @bytebytego
131K Followers 2 Following Weekly system design topics you can read in 10 mins.
Supabase @supabase
200K Followers 99 Following The Postgres development platform. 🌐 https://t.co/kHsst88XA1 ⭐️ https://t.co/txGagqok1i 🎥 https://t.co/6eTjCTIrzK 💬 https://t.co/ikFm89oPVI
DaveDisaster @davedisasterman
284 Followers 395 Following Web developer, Lego obsessive, abusive compère, intrepid space explorer, maker of tabards and flags... He, him, his, YDY.

John Crickett @johncrickett
13K Followers 996 Following Helping software engineers become better software engineers by building projects. With or without AI.
shadcn @shadcn
225K Followers 402 Following I own a computer / Working on https://t.co/HJcOr0AUAr & https://t.co/5FRvxukoY5.
Irina Stanescu @thecaringtechie
2K Followers 827 Following Writing "The Caring Techie Newsletter" Teaching "Impact through Influence" on Maven Eng Leader / Leadership Coach ex-@Google, ex-@Uber.
Luca Rossi ꩜ @lucaronin
11K Followers 533 Following 💧 Maker of @tolariamd • 📬 Author of https://t.co/mtplxYVm9C • I write weekly about shipping software with AI to 170K+ engineers.
Gergely Orosz @GergelyOrosz
337K Followers 3K Following Writing @Pragmatic_Eng, the #1 software engineering newsletter on Substack. Author of @EngGuidebook. Formerly Uber & Skype.
Neo Kim @systemdesignone
50K Followers 147 Following I Teach You AI & System Design • 0.5M+ Audience
Dr Milan Milanović @milan_milanovic
63K Followers 3K Following Chief Roadblock Remover and Learning Enabler | Helping 400K+ engineers and leaders grow through better software, teams & careers | Author of @SoftwareEngLaws
Jecelyn Yeen 🐟 @jecfish
9K Followers 409 Following Principal Software Engineer. Ex-Googler. Ex-Chrome. 👩💻🇲🇾🤿
Biome @biomejs
10K Followers 9 Following Official account of the Biome project. Discord: https://t.co/yCYMQLPCUQ Github: https://t.co/KAFEnnsN8JYou might like



















