

SELECT @select_dev
The Snowflake optimization and cost management platform. Follow to hear about our latest Snowflake learnings. select.dev 🇨🇦 & 🇬🇧 Joined July 2022-
Tweets56
-
Followers277
-
Following5
-
Likes12

Great Thank you🥰 @NiallWoodward @ianwhitestone @select_dev #SnowflakeSummit #DataCloudSummit


Huge if true.
uhhh, this query just ran successfully in @SnowflakeDB. LFG. IYKYK

increase your dbt thread count, you should
Thanks for sharing! Wrote about this in more detail here for those curious: select.dev/posts/snowflak…
SELECT Cloud、3ヶ月ほど運用したので満を持して、事例公開しました。 OSS版も素晴らしいですが、Cloudはもっとすごいので、Snowflakeのコストやパフォーマンスで、お困りの方は、是非チェックしてください🥰 @SnowflakeDB_jp @SnowflakeDB @select_dev

❄ SELECT Cloud国内初導入!❄ Snowflake使用コストを最大40%最適化 SELECT Cloudについて @pei0804 が導入実績を解説! > 利用料を40%程度削減できてるワークロードも出てきて、この節約機能だけで、SELECT Cloudの利用料を回収できてしまうレベルのインパクトでした。 techblog.cartaholdings.co.jp/entry/select-c…
We finally got some time to I finally got some time properly reflect on everything @SnowflakeDB announced last week at Summit 2023. Learn about every announcement and our thoughts on each in our latest post👇 select.dev/posts/summit-2…
Back in March we had the opportunity to speak at @datacouncilai in Austin. We had a blast sharing everything we've learned about @SnowflakeDB cost and performance optimization. Slides & recording now available 👇 select.dev/posts/data-cou…

Geeking out about Snowflake optimization with the @select_dev crew @NiallWoodward and @ianwhitestone. 5/7

New @dbt_labs Analytics Engineering Podcast is LIVE🎙️! @jthandy and I sit down with @brad_culberson from @SnowflakeDB and @NiallWoodward from @select_dev to talk about cloud warehouse optimization. Listen for practical advise on a top of mind topic 🧠🫰 open.spotify.com/episode/2j8Djh…
Was about to tweet our latest post but @toppare bet me to it 🏃♂️. Thanks for sharing! Curious about when to use CTEs in Snowflake? Read on!
Another great post from @select_dev about CTEs. Summary: - continue using CTEs 🤘 - specify column names (don't "import" with select *) - for special queries, experiment with repeating logic instead of reusing CTEs - learn how to read query plan select.dev/posts/should-y…

We're two weeks out from the next Analytics Engineering meetup in London at the @thoughtmachine office. 🙏Big thank you to our friends over @SpectaclesCI and @select_dev for letting us support such a great event! The countdown to grab your seat is on! 👉 bit.ly/3Izk2hj
🗣️UK friends: The next Analytics Engineering meetup is approaching fast! 🤝We’ve joined forces with @SpectaclesCI and @select_dev in co-hosting this event at @thoughtmachine in London, March 23 at 6pm GMT. Save your seat 👉bit.ly/3Izk2hj
@SnowflakeDB query tags are indeed awesome. We recently covered them in depth for those wondering why and how they should use them: select.dev/posts/snowflak…
Another great post from @select_dev about CTEs. Summary: - continue using CTEs 🤘 - specify column names (don't "import" with select *) - for special queries, experiment with repeating logic instead of reusing CTEs - learn how to read query plan select.dev/posts/should-y…
⚠️ Unfortunately, this function isn't guaranteed to be deterministic. As a result, it won't be able to leverage Snowflake's result cache, so be careful when using in performance or cost sensitive applications where the query is executed frequently.
More generally, you can use these to find the row containing the min/max value for a particular column, then return the value of another column in that row.
In @SnowflakeDB 's latest release, they've given us a nice new set of aggregate functions: min_by and max_by. In this example I look across each user's query history, and find the ID of the first and last queries they executed.
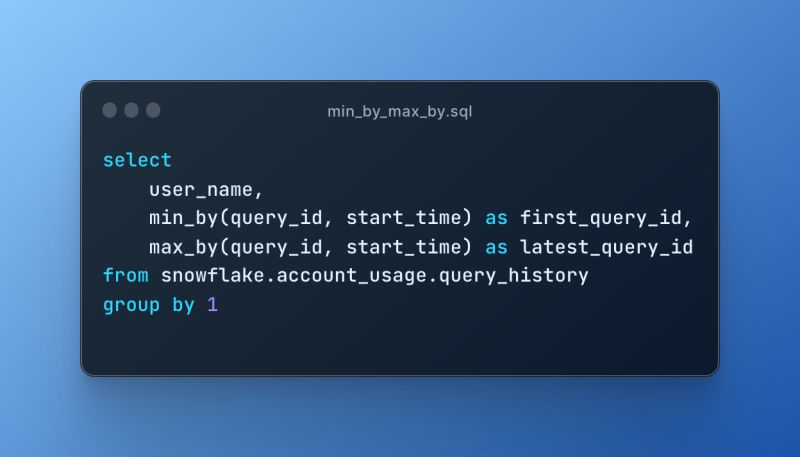
All the details are in here 👇 select.dev/posts/snowflak…
Range joins are notoriously slow in many databases. @SnowflakeDB is no exception. We're using a binned range join technique across a number of models in our @getdbt project and have seen incredible results. A 300x speedup for this query.



Jacob Matson @matsonj
8K Followers 2K Following excel user & data enthusiast. living the dream at MotherDuck
Rahul Jain @rahulj51
4K Followers 2K Following Engineering Manager, AI Data Products at @justbobsledit. Formerly led Data and Engineering at @thebeatapp , @omioglobal , @thoughtworks .
Barry McCardel @barrald
4K Followers 987 Following co-founder and CEO of Hex (https://t.co/hbgguInF1h / @_hex_tech) - former @PalantirTech @formationbio - personal site: https://t.co/c38nDG5Dfl
Jake Hannan @_jhannan
1K Followers 3K Following data + product @sigmacomputing; helping teach @corise_; optimistically sporadic; thoughts are randomly generated
leo @leoebfolsom
2K Followers 2K Following
zʇǝɥɔ uɐɹe @eranchetz
293 Followers 832 Following Global VP of FDE Delivery @doitint. Ex @CheckPointSW, Ex @algolia Blog: https://t.co/G6VydfVdwm My teams blog: https://t.co/OPAF9kURwc
Emran.py @Emran_py
17 Followers 332 Following millions up, autistic, deep in tech & games, grateful beyond words. brain runs weird but it works. mostly.

mehnz ~ @fiatluox
9 Followers 1K Following
Ian @dosesofdata
9 Followers 132 Following

Brian Barela @brianbarela
2K Followers 3K Following Artificial Intelligence & Data Pro - GenAI Product Manager @ https://t.co/K9Xos1QHh6
たかぴ(三橋尚... @prm_mitsuhashi
176 Followers 422 Following 株式会社パートナープロップ データエンジニア|パートナーマーケティングを実現する PRM ツール「PartnerProp」を開発|採用、プレミアリーグ、たまにデータエンジニアリングについて発信|趣味はプレミアリーグ観戦・ワイナリー・ブリュワリー巡り

Jjj @all_your_jjj
17 Followers 62 Following
Michel Wesseling @michelwesseling
155 Followers 111 Following
Sunset Holdings @SunsetHoldings
24 Followers 3K Following
Yglausu @Yglausu1007
21 Followers 1K Following
Francisco Debs @ciscodebs
323 Followers 2K Following Growth @themansion_life. Prev: OG of Marketing, Product, and Data at @RedVentures
Wonderful Sunrise @WonderfulS68790
0 Followers 24 Following

koreeda @cs_dev_engineer
1K Followers 694 Following Bioinformatics Scientist, Snowflake Data Superhero 2026, サイエンスデータエンジニアリングラボ運営者 お仕事・大学講義・登壇・執筆のご依頼は DM または リプライにて
Indigo guardiola @Indiguardiola
235 Followers 5K Following
Yaniv Leven @yanivleven
199 Followers 157 Following Now CPO at SeemoreData, formerly CEO @ Panoply (Acquired). SaaS | Cloud | Product | Data | GTM | Innovation | psychology and football - https://t.co/6p2UaeyID1
田中 信行 | Adval... @nobuyuki_t
176 Followers 1K Following アドバリスター(株)代表 | アクセンチュア→海外アドテクスタートアップ日本法人→ 事業開発支援コンサル → B2B SaaSスタートアップ 取締役 → 現職 | データ利活用支援、事業開発支援(新規・グロース)等をやってます。ご相談はお気軽にDM下さい!


Bhavdip Pambhar @bbpambhar
387 Followers 847 Following Laravel Engineer | Cricket Lover | Ambitious | Dreamer 🇮🇳
Advi Rao Kulkarni @adhvirao
11 Followers 72 Following
David Crow @davidcrow
12K Followers 4K Following Connector of dots. Maker of lines. Rider of slopes. Kinda sendy, dad. (he/him) 🇨🇦/acc
@calendarinvite @31events
686 Followers 5K Following We built the AWS Calendar Invite Server for 1000's of developers. https://t.co/b4SjxyB6d1. Bootstrapped in Colorado.

hershcules @hershcules
482 Followers 1K Following Operating Partner + fintech investor @fikavc, founding team @jetblue, BD/sales @factual and @yodlee.
Aaron Morelli @sqlcrossjoin
102 Followers 24 Following The Eternal Gospel cross join'd with a 20+ year old product from Microsoft.
Greg Finley @gregoryfinley
284 Followers 2K Following I was born the day Len Bias died. Journalist turned analyst turned software engineer. Patiently awaiting the final Robert Caro LBJ book.
dawgman @moondawgpp
19 Followers 328 Following
harry @gappy50
2K Followers 3K Following データエンジニアリング&プロレスラー&イッヌ(柴犬)の動向を確認するサイコパスアカウント/2022-2026 Snowflake Data Superheroes

John Dutchover @johndutchover
181 Followers 791 Following
@sinclaw @sinclaw
25 Followers 715 Following
Kevin @Kevinrobot34
3K Followers 1K Following VP of Data & AI @ Finatext Holdings / Data Platform Engineer @ Nowcast / Snowflake Data Superhero 2026 / Kaggle Competition Master
Victor Perez Pereira @vperezpereira
444 Followers 244 Following AWS Data Community Builder, AWS Community Leader
luis carhuarica @totodj_13
54 Followers 3K Following



Ryuichi Shimajiri @rshimajiri_
249 Followers 247 Following Data Engineer at Nowcast Inc. / SnowPro Advanced: Architect & Administrator / Snowflake Squad 2025 / アイコンは趣味のかな書道 / ※ここでの発言は私個人のものであり、所属する組織を代表するものではありません。
DCyr @cyrdg
11 Followers 70 Following
Sonny ☀️ with a c... @rqrivera
187 Followers 302 Following Sr. Analytics Evangelist at ThoughtSpot | Thought Leader 🤔| Data Head | Data SuperHero | Guitarist 🎸 | Author✍ | #data #analytics #moderndatastack #datavault
Pietro Casella @PietroCasella
284 Followers 2K Following “the AI guy” at MGX. I try a new software every day. ex. EQT Motherbrain, Spotify, KPMG, Accenture
Elon Gliksberg @elongli
259 Followers 3K Following

Abe Gong @AbeGong
3K Followers 2K Following geek dad with a clipboard founder @ Katabase and Great Expectations operating advisor @ Bessemer VP data, ai, startups, dev tools, systems thinking storytel
abenben.eth @abenben
4K Followers 5K Following あべんべん(阿部 一也)として、自律型分散型社会(DAO)の実現を目指し、金融・技術・政策・管理の各分野で得た知見を幅広く発信しています。 プロフィール: https://t.co/VsPT46zNji note: https://t.co/pNWj4foMM0

Snowflake @Snowflake
64K Followers 1K Following The AI Data Cloud where data does more, and proud to be the Official Data Collaboration Provider for LA28 and Team USA.
Baran Toppare 🧟... @toppare
372 Followers 958 Following Data @RevenueCat Knowledge is ephemeral, curiosity is not.
dbt @getdbt
15K Followers 69 Following 🏗 Your entire analytics engineering workflow 🧪 Built by @dbt_labs
Trends for United States
You might like













